Merging Strategies in GitHub
Different projects use different git merging strategies. Even though this post is really talking about git itself, you can use this information without actually using GitHub. It also applies to any other online Git frontends like Bitbucket as well.
TLDR: If you need to maintain all commit IDs in your branches after they are merged/deleted you must use Create a merge commit. If it’s an open source project with contributors, Squash and merge is the best choice. If it’s a private repo where you can control the engineers Rebase and merge is a good choice, however Squash and merge also works just as well.
Merge Options
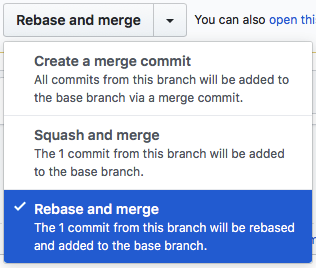
| The following dropdown is presented when the arrow to the right of the merge button is clicked: |
|
|---|---|
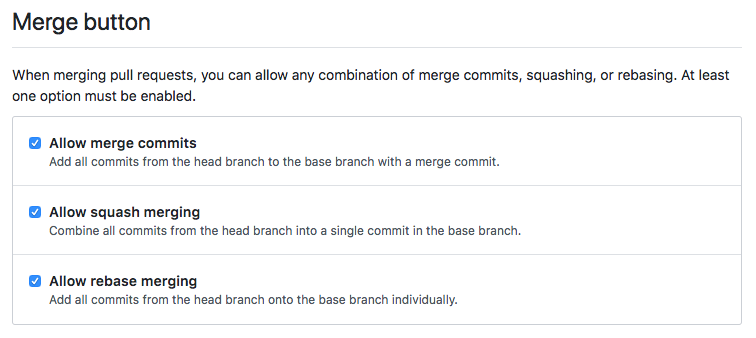
| Merge button options can be restricted on the Repository Settings page: |
|
Merge Option Comparison
Each strategy has its own advantages and disadvantages. This table is worded in a way where a ✅ generally means it does that task/option/thing better. However, that’s not strictly true in all cases. In fact, you may specifically not want it to have that feature.
| Topic | Create a Merge commit | Squash and merge |
|---|---|---|
|
The history is never modified, so commit IDs will always stay persistent. If your repository, build system, delivery pipeline, bundled application versions or documentation relies on commit IDs staying the same in your entire history (including deleted feature branches) then this can be a deal breaker that means you have to use Create a merge commit. It's important to note that rewriting history (if done correctly) should only affect the feature branches before they are merged into you main or stable branch. You would only rewrite history on the main branch if something went terribly wrong (such as passwords got accidentally committed and merged). |
✅ | ⛔ |
|
If you have a CI system running your tests (such as Travis CI), it will be likely be trigged when you push code. However, it does not test every commit, only the most recent. This means it's possible to push 5 commits where 4 of them cause a failure in the build system but the 5th one passes. A common scenario is when a build fails for a minor reason like a style check. People will push fixup commits like "fixing code style" or the dreaded "minor". Eventually the build will pass but all those broken commits will be merged in with the feature. If you need to rerun a build or use |
⛔ | ✅ |
|
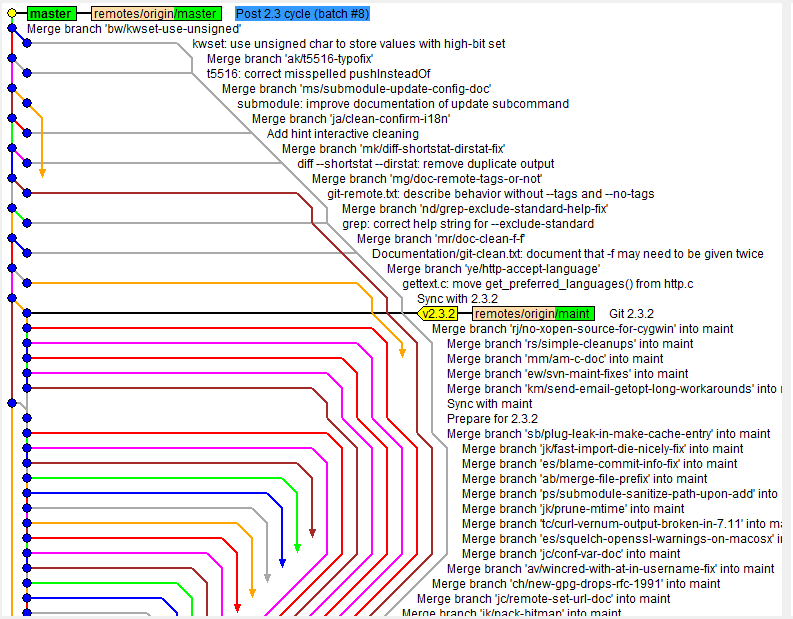
Branching in git is cheap, easy and wonderful. Even in mid-sized projects with a handful of developers using the Create a merge commit strategy can lead to a very convoluted history that's often impossible to follow. For example:
Keeping a linear commit history requires that branches will have to be rebased or collapse their commits on top of the latest head of the branch they wish to merge into. This changes the history (and therefore commit IDs) of the branches, but it also provides a single line of history that is much easier to follow and understand. |
⛔ | ✅ |
|
Even though nothing is really deleted in git and you can always recover a bad rebase using the This is often why projects opt for simple merge commits. It's about as full proof as you can get in terms of preventing the engineer from getting into sticky situations. |
✅ | ✅ |
|
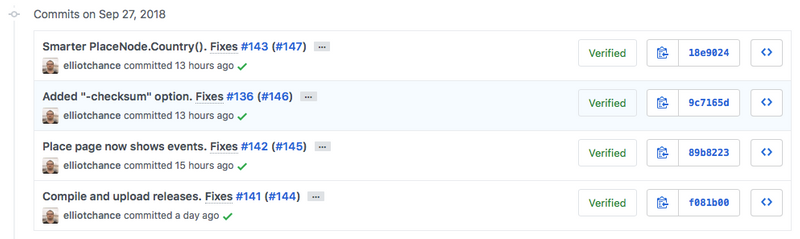
This can be very important for open source projects where all of the issues and discussions are in GitHub itself. GitHub will automatically recognize issue and PR numbers in the form of "#123" in your commit messages and create real links back to those entities. Except for Rebase and merge, GitHub will include these automatically for you in the commit messages making it much nicer and easier when exploring the commit history to identify why things were changed.
|
✅ | ✅ |
|
Referencing back to Avoids introducing commits that break in CI, people that are not comfortable with rebasing will often create new commits to fix up the tests or builds. These are of no use in your history and actually make it harder to locate the real commit that made the genuine change to identify the motivation or description. This is where Squash and merge really shines and works great in open source projects where the experience of engineers will vary and all changes will be put together in a single commit with a link back to the issue and/or pull request. |
⛔ | ✅ |
|
Rebasing (especially for those new to git) can sometimes be a more complicated way to deal with conflicts because you are dealing with lots of small conflicts that affect conflicts further down the line. We have all done it. When you realized halfway through a rebase that you have chosen the wrong side and you will be dealing with that same conflict many more times. If your project is dealing with external engineers or less experienced engineers it can be tough to enforce and make sure they have a nice rebase history. |
✅ | ✅ |
|
Sometimes you want to edit the commit message when merging. To fix spelling mistakes, adding extra ticket numbers, etc. Squash and merge is great for this. |
⛔ | ✅ |
| ✅ | ⛔ |